[TOC]
📖 简介
ants是一个高性能的 goroutine 池,实现了对大规模 goroutine 的调度管理、goroutine 复用,允许使用者在开发并发程序的时候限制 goroutine 数量,复用资源,达到更高效执行任务的效果。
💡 为什么要使用goroutine 池
Go自从出生就身带“高并发”的标签,其并发编程就是由groutine实现的,因其消耗资源低,性能高效,开发成本低的特性而被广泛应用到各种场景,例如服务端开发中使用的HTTP服务,在golang net/http包中,每一个被监听到的tcp链接都是由一个groutine去完成处理其上下文的,由此使得其拥有极其优秀的并发量吞吐量。
一般情况下,goroutine在操作系统上只要你的硬件资源够它是可以无限启动的。但是如果出现大规模的启动goroutine的情况会造成大量占用系统资源,我们知道普通的部署一个golang应用的时候操作系统不仅仅会运行golang程序还有其他辅助的程序运行,所以理论上讲工作池的目的就是为了限制golang的启动数量,保证不会出现硬件计算资源溢出的情况。
👀 源码解读
运行流程

可以看出anst总共分为两大模块pool 和worker
pool用于存储worker,worker用于执行任务。
pool分为普通的pool 和pool_func
pool可以向其提交不同的func() 来执行任务,
pool_func,其 在初始化的时候要提供一个func(interface{}),此后每次提交只提交参数即可,ants会自动运行初始化的函数。
options
options包用于设定池的一些参数。值得注意的是Option是func(*Options)是一个函数,Options才是保存池信息的结构体变量。
Options的结构体
type Options struct {
//ExpiryDuration是清除程序goroutine清理那些过期的 worker 程序的时期, //清除程序每隔`ExpiryDuration`扫描所有 worker ,4
//并清理那些没有被使用超过`ExpiryDuration`的 worker 。 //这是为了防止大量的不使用的worker过多的占用内存,程序动态的调整worker的数量
ExpiryDuration time.Duration
// PreAlloc指示在初始化Pool时是否对内存进行预分配
PreAlloc bool
// 在pool.Submit上阻塞goroutine的最大数量。 // 0(默认值)表示没有此限制
MaxBlockingTasks int
// 当Nonblocking为true时,Pool.Submit将永远不会被阻塞。 // 当无法一次完成Pool.Submit时,将返回ErrPoolOverload。 // 当Nonblocking为true时,MaxBlockingTasks不起作用。 Nonblocking bool
// PanicHandler用于处理每个工作流程中的Panic。 // 如果为nil,Panic将再次从工作人员goroutine中抛出。 PanicHandler func(interface{})
// 日志接口
Logger Logger
}
options包下的函数都是用于返回一个Option用于设定Options ,不做过多描述。
pool
pool的结构体,其用来记录pool的一些信息,可通过传入options来进行改变
type Pool struct {
//池的容量,负值表示池的容量是无限的, capacity int32
// running是当前正在运行的goroutine的数量。 running int32
// workers is a slice that store the available workers.
// 存储提交的woeker
workers workerArray
// 标示pool的状态(关闭或者打开) state int32
// lock for synchronous operation.
// sync.Locker为一个🔒接口,需要实现其Lock,Unlock方法
lock sync.Locker
// cond for waiting to get a idle worker.
// 用于worker执行调度具体用法见 https://ieevee.com/tech/2019/06/15/cond.html
cond *sync.Cond
// workerCache在function:retrieveWorker中加快了可用worker的获取
workerCache sync.Pool
// blockingNum是已在pool.block上被阻塞的goroutine的数量,受pool.lock保护
blockingNum int
options *Options
}
NewPool 初始化函数
// NewPool generates an instance of ants pool.
func NewPool(size int, options ...Option) (*Pool, error) {
// 传入多个Option用于设定池的参数,返回一个配置实例
opts := loadOptions(options...)
// 池的容量,负数为无限大
if size <= 0 {
size = -1
}
if expiry := opts.ExpiryDuration; expiry < 0 {
// 如果扫描时间小于0,抛出错误
return nil, ErrInvalidPoolExpiry
} else if expiry == 0 {
// 如果等于0(即并没有设定)采用默认值1s
opts.ExpiryDuration = DefaultCleanIntervalTime
}
if opts.Logger == nil {
// 如果没有实现日志接口,采用默认的日志打印器
opts.Logger = defaultLogger
}
// 实例化一个pool对象
// lock 为internal包下实现的一把自旋🔒,实现较简单,不做表述。 p := &Pool{
capacity: int32(size),
lock: internal.NewSpinLock(),
options: opts,
}
// 初始化一个 sync.Pool ,创建对象的函数
// 易看出 sync.Pool缓存的是一个worker(结构体名为goWorker)对象。 // worker下文进行解释
p.workerCache.New = func() interface{} {
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
// 如果对内存进行预分配则采用队列的形式进行调度不然采用栈的形式
// workerArray为一个接口,不同的形式有不同的方法实现
// size会限制workerArray中空闲worker队列的长度,过小的长度会导致性能问题(我认为) if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
p.workers = newWorkerArray(loopQueueType, size)
} else {
p.workers = newWorkerArray(stackType, 0)
}
// 实例化一个cond
p.cond = sync.NewCond(p.lock)
// 启动goroutine定期清理过期的worker。 go p.purgePeriodically()
return p, nil
}
在初始化函数中,初始化了一个pool必须的资源,同时对其绑定了不同的调度方法。
purgePeriodically() 定期清理函数
func (p *Pool) purgePeriodically() {
// 定时器,每隔ExpiryDuration执行一次
heartbeat := time.NewTicker(p.options.ExpiryDuration)
defer heartbeat.Stop()
for range heartbeat.C {
// 如果池已关闭,跳出清理循环
if atomic.LoadInt32(&p.state) == CLOSED {
break
}
p.lock.Lock()
// 调用workerArray的清理函数,返回被清理的对象切片
expiredWorkers := p.workers.retrieveExpiry(p.options.ExpiryDuration)
p.lock.Unlock()
//通知过时的Worker停止。
//此通知必须在p.lock之外,因为w.task可能正在阻塞, //并且如果许多Worker位于非本地CPU上,则可能会花费大量时间。 for i := range expiredWorkers {
expiredWorkers[i].task <- nil
expiredWorkers[i] = nil
}
//可能会清理所有工作程序(没有任何工作程序正在运行) //某些调用程序仍然卡在“ p.cond.Wait()”中, //应该唤醒所有这些调用程序
if p.Running() == 0 {
p.cond.Broadcast()
}
}
}
其清理流程为每隔一定的时间调用一次清理,先获取一次过期的worker,再将其释放掉,因为每个worker都在等待task管道,故可通过传入nil退出,详细可见worker.go 64行附近。同时,应为w.task可能正在阻塞,会导致expiredWorkers[i].task <- nil也堵塞,这就会导致锁长时间得不到释放,会极大的影响性能,故应在锁外进行通知woker停止。
retrieveWorker 返回一个可用的工作程序来运行任务
在看submit前必须先了解retrieveWorker
// retrieveWorker returns a available worker to run the tasks.
func (p *Pool) retrieveWorker() (w *goWorker) {
// 定义一个取worker的函数其是在缓存中拿
spawnWorker := func() {
// 获得一个worker对象
w = p.workerCache.Get().(*goWorker)
// 开始run,等待任务的分配
w.run()
}
p.lock.Lock()
// 从队列中拿出一个worker
w = p.workers.detach()
if w != nil {
// 如果拿到了,直接退出就是了
p.lock.Unlock()
} else if capacity := p.Cap(); capacity == -1 {
// 如果容量不设上限 直接从缓存中拿
p.lock.Unlock()
spawnWorker()
} else if p.Running() < capacity {
p.lock.Unlock()
// 如果没到容量上限 直接从缓存中拿
spawnWorker()
} else {
if p.options.Nonblocking {
// 如果是不阻塞的,不执行任务返回nil
p.lock.Unlock()
return
}
Reentry:
if p.options.MaxBlockingTasks != 0 && p.blockingNum >= p.options.MaxBlockingTasks {
// 如果阻塞任务过多也返回空
p.lock.Unlock()
return
}
p.blockingNum++
// 等待被唤醒
p.cond.Wait()
p.blockingNum--
// 因为如果running()==0 肯定p.workers.detach()是拿不到的故在池子里拿一个
// 题问:为什么不是p.Running()<capacity? if p.Running() == 0 {
p.lock.Unlock()
spawnWorker()
return
}
w = p.workers.detach()
if w == nil {
// 反复去拿到一个worker去执行
goto Reentry
}
p.lock.Unlock()
}
return
}
在retrieveWorker中主要用于获取一个worker去执行任务,同时根据用户的配置去限制获取。在并发条件下锁的位置很重要,锁会带来安全但也会降低性能。
Submit 提交任务
// Submit submits a task to this pool.
func (p *Pool) Submit(task func()) error {
if atomic.LoadInt32(&p.state) == CLOSED {
return ErrPoolClosed
}
var w *goWorker
// 获得一个可用的worker 将任务发送给worker去执行
if w = p.retrieveWorker(); w == nil {
return ErrPoolOverload
}
// 直接通知执行
w.task <- task
return nil
}
revertWorker 将一个worker空闲队列
// revertWorker将工作人员放回空闲池,从而回收goroutine。func (p *Pool) revertWorker(worker *goWorker) bool {
if capacity := p.Cap(); (capacity > 0 && p.Running() > capacity) || atomic.LoadInt32(&p.state) == CLOSED {
return false
}
// 更新worker的最后活动的时间
worker.recycleTime = time.Now()
// 因为要对Worker队列进行操作,上锁保证并发安全
p.lock.Lock()
// To avoid memory leaks, add a double check in the lock scope.
// 为避免内存泄漏,请在锁定范围内进行仔细检查。 // Issue: https://github.com/panjf2000/ants/issues/113
if atomic.LoadInt32(&p.state) == CLOSED {
p.lock.Unlock()
return false
}
// 插入操作具体由`workerArray实现
err := p.workers.insert(worker)
if err != nil {
p.lock.Unlock()
return false
}
// Notify the invoker stuck in 'retrieveWorker()' of there is an available worker in the worker queue.
p.cond.Signal()
p.lock.Unlock()
return true
}
此方法在goWoker.run()中使用,每次执行完任务都会将其丢到队列末尾,等待下一次调度,同时更新recycleTime便于清理无用worker ,同时调用p.cond.Signal()通知阻塞任务可以进行调度了。(cond好像并不是Wait(),和Signal()一一对应的,按照这个代码,Signal()调用次数是远大于Wait()的)
Running 返回正在执行的worker
Free 返回空闲的worker
Cap 返回容量
Tune 调整池的容量
Release 关闭pool
通过调用workerArray.reset()进行清空workers来实现worker的关闭,同时标记pool的状态为CLOSED
Reboot 重启pool (ps:感觉如果反复开关pool会导致有多个清理函数执行啊🤣)
incRunning running++
这个操作利用atomic包进行操作,保证并发条件下数据的准确性,下同。
decRunning running--
worker
worker的结构
type goWorker struct {
// pool who owns this worker.
// 这个worker的主人🤣
pool *Pool
// 任务管道
task chan func()
//worker重新放入队列时,recycleTime将被更新。
recycleTime time.Time
}
结构很简单,主要一个就是用于进程通信的chan
run 运行
func (w *goWorker) run() {
// 计数器加一
w.pool.incRunning()
// 开启一个goroutine运行任务
go func() {
// 析构函数
defer func() {
// 计数器--
w.pool.decRunning()
// 将无用的worker放入缓存池
w.pool.workerCache.Put(w)
// 处理程序出现的panic
if p := recover(); p != nil {
if ph := w.pool.options.PanicHandler; ph != nil {
ph(p)
} else {
w.pool.options.Logger.Printf("worker exits from a panic: %v\n", p)
var buf [4096]byte
n := runtime.Stack(buf[:], false)
w.pool.options.Logger.Printf("worker exits from panic: %s\n", string(buf[:n]))
}
}
}()
// 等待chan发送任务
for f := range w.task {
// nil主要由purgePeriodically()发送,通知worker可以关闭了。 if f == nil {
return
}
// 执行任务
f()
// 执行完毕,将worker加入`workerArray`的空闲队列,如果加入失败则退出,避免造成内存泄露
if ok := w.pool.revertWorker(w); !ok {
return
}
}
}()
}
其run函数维护了pool的Running,同时也考虑到了panic的发生(panic如果不处理是会导致程序直接挂掉,小心goroutine),同时,每次执行完毕将worker加入workerArray的空闲队列,这样就将worker管理起来了。
如图 worker 的流程
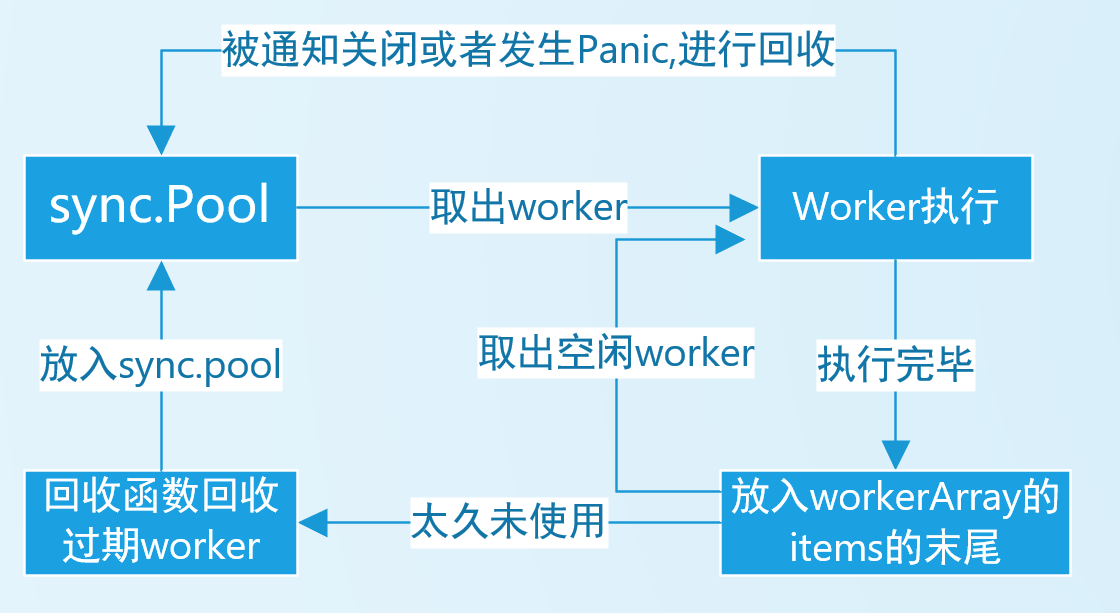
workerArray
workerArray 是一个接口 一些方法上文中已多次提到,值得一提的是,作者自己用切片实现了循环队列和栈两种,很值得学习。
type workerArray interface {
// 获取空闲队列的长度
len() int
// 是否是空的
isEmpty() bool
// 尾插一个worker
insert(worker *goWorker) error
// 获取一个worker 获取失败则返回nil
detach() *goWorker
// 获取过期的worker队列,在purgePeriodically()调用
retrieveExpiry(duration time.Duration) []*goWorker
// 停止worker(正在执行的任务不会停止,只是当任务执行完毕不再接受下一个任务,会退出),清空workerArray
reset()
}
worker_loop_queue 和 worker_stack实现了这些方法,是很基本的数据结构,但是由三点值得注意
- 这不是并发安全的,所以在调用这些方法的时候要上锁。
worker_loop_queue的大小是确定的,如果短时间要执行的任务太多,会被堵塞或者返回nilitems []*goWorker在items中的都是空闲的 worker,expiry []*goWorker中不保存数据,只是一个用来临时返回过期worker的切片,为避免频繁创建切片。
🤔总结
有必要讲一下workers的设计,每一个worker都在run(),run()代表其正则执行任务或者正在监听等待任务,worker的创建和删除是依赖于sync.Pool的,当需要一个worker,就在workers队列中拿,拿不到就从sync.Pool中拿,每停止一个worker就放一个worker回去,sync.Pool被官方设计为一个高性能的复用缓存池,有效的避免了反复进行worker对象的创建和删除。
还有sync.Cond的使用,假设不使用cond,新任务如果被阻塞了,一般都是用一个range一个chan 抢占式地去获取一个worker去执行,当过多的任务去抢占一个worker,会浪费cpu的性能。其通过cond唤醒一个或者多个去抢占worker,减少性能损耗。
atomic ,用来保证数据的原子操作,在ants中经常可以看到这个库的使用,因为ants是设计为在高并发情况下的调度程序,数据的原子操作很重要,同时,ants中的自旋锁也是基于此来实现的。
系统中优良的接口设计,好的接口设计可以很明确系统的功能,同时也利于代码的修改和解耦。这是很值得去学习的。